When the chatbot sounds sure—but you still don’t trust it
You roll out a chatbot for support or internal Q&A, and it answers in complete sentences with a clean, confident tone. Then someone tests a few edge cases and it slips: a policy detail is wrong, a number is off, or it cites a feature you don’t offer. The output still sounds certain.
That gap creates a practical problem: teams either over-trust and ship mistakes, or under-trust and waste time rechecking everything. You also pay a hidden cost when leaders can’t explain the behavior, because every miss turns into a debate instead of a fix.
What you’re actually buying: a prediction machine, not a knowledge store
Making it dependable starts with naming what it is. A generative model isn’t pulling an answer from a stored set of facts the way a database or policy wiki does. It’s generating the next likely words based on patterns it learned, then repeating that step until it has a full response.
That’s why it can sound crisp and still be wrong. If the prompt resembles thousands of past “how do I reset my password?” threads, you’ll get a smooth, plausible procedure—even if your product changed last month. If the question is rare or mixes details (“EU refund rules for annual plans on a legacy tier”), the model fills gaps with whatever looks most likely in the moment.
In practice, you’re buying a probability engine with a great writing voice. The hard part isn’t banning mistakes; it’s knowing when “likely” stops being safe and certainty needs to be earned.
Why certainty isn’t an on/off switch in real work
In real workflows, “earned” certainty comes in slices, not a single switch you flip. A support agent can safely use an answer that’s 95% right for a password reset, but that same margin is unacceptable for a cancellation fee, a compliance claim, or a customer’s invoice. The model doesn’t change modes just because the stakes changed; it keeps predicting words.
If the question is specific and the relevant details are in the prompt or your docs, outputs tend to stabilize. If the question is underspecified (“Can we refund this?”) or combines moving parts (region, plan, contract date, promo credits), the model has to guess what’s missing. Small changes in wording can shift the guess, and you can get different answers that all sound confident.
That’s why reliability means deciding where “good enough” is, and spotting the situations where probability stops behaving like a helpful shortcut.
Spotting the moments when probability will betray you

That “helpful shortcut” breaks in the same places your team already dreads: when a ticket is missing one key detail, or when the answer depends on a rule that changed recently. If the model doesn’t have the missing piece, it won’t pause and ask by default. It will pick the most common scenario and keep going, which is how “sounds right” turns into the wrong refund window or the wrong plan name.
Watch for three tells. First, questions that bundle variables (“enterprise customer in Germany, annual plan, mid-cycle upgrade”) because one wrong assumption flips the outcome. Second, anything with exact numbers, dates, or thresholds—fees, limits, SLA times—where a single digit matters. Third, anything that requires a source of truth outside the prompt: current pricing, policy exceptions, account status. In those moments, probability won’t fail loudly; it will fail smoothly, and that’s the cue to force verification.
The uncomfortable truth: verification is part of the product
“Force verification” usually lands as an extra step that slows things down. In practice, it’s the step that keeps a smooth wrong answer from becoming a customer promise, a bad invoice, or a compliance headache. Once you put a chatbot into a workflow, you’re no longer just shipping text. You’re shipping a decision aid, and it needs a way to prove itself when the question touches money, policy, or timing.
The shift is to treat verification like a product feature, not a human workaround. That can be as simple as requiring a citation to an internal doc before the bot can mention a fee, a refund window, or an SLA. Or forcing a quick “missing info” check: region, plan, contract date, account status. If any are absent, the bot must ask, not guess.
Someone has to maintain the source docs, handle exceptions, and decide what counts as “verified.” But that work is what turns probability into something you can run at scale—without risking your operations on a confident tone.
Guardrails that don’t kill speed (prompts, retrieval, and fallback paths)
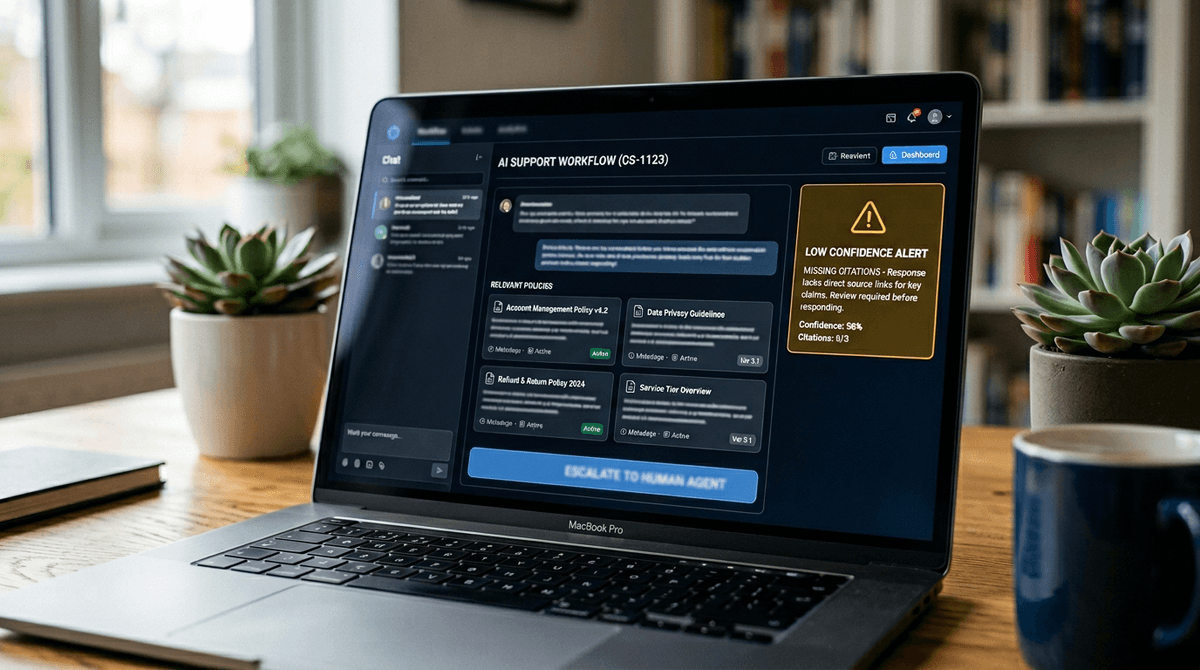
That maintenance work gets lighter when you stop relying on “be careful” and instead build guardrails into the flow. In a typical support queue, the fastest teams don’t read every answer twice. They structure the question so the model has fewer ways to guess, and they make “I don’t know yet” a valid outcome.
Start with prompts that force assumptions into the open: “List required inputs; if any are missing, ask for them.” Add “If the answer involves fees, dates, limits, or eligibility, quote the exact policy text and name the source.” Then use retrieval (RAG) so the model pulls from your current docs, not its memory. Keep the retrieval set small and owned—two conflicting policy pages will produce clean, wrong certainty.
Finally, define fallback paths. If confidence is low or citations are missing, route to a human, a rules engine, or a “here’s what I can confirm” template. The next step is deciding where those paths become the default, not the exception.
How to make peace with probability—and still run a dependable operation
Those fallback paths become the default whenever a wrong answer would create a promise your team can’t unwind. In practice, that means you don’t ask the model to be “more accurate.” You decide what it’s allowed to do without proof, and what requires a source, a check, or a handoff.
Run it like an operations system: define tiers (draft, suggested, approved), log when humans override, and review the top failure patterns weekly. Then fix the cause—missing fields in the intake form, outdated docs, or a retrieval set that’s too broad. More instrumentation, more doc ownership, and occasional slower loops. The payoff is steady behavior you can explain, measure, and trust.











